
Learning how to make AI for your business has become essential for staying competitive. According to Statista, AI is expected to contribute over $15.7 trillion to the global economy by 2030. That kind of growth makes one thing clear: companies that invest in building AI with the right intent and execution stand to gain real, lasting value.
Making AI has become more accessible with modern development tools and frameworks. You need a clear process, the right tools, and practical guidance that cuts through the complexity.
Many CTOs and product managers avoid building AI because they believe it requires massive resources and expertise they don’t have. This creates dependency on external vendors and limits their ability to create competitive advantages. But with the right approach, AI development is more achievable than most teams realize.
This guide shows you how to approach AI development with a clear business objective. You’ll learn when in-house development is strategically justified, how to structure your process, and what steps to take from concept to production. By the end, you’ll have a clear roadmap for making AI that drives measurable results for your organization.
Key Takeaways
- Start with a well-defined business problem; AI only works when it solves a specific issue.
- Your data strategy matters more than your algorithm; clean, diverse datasets are non-negotiable.
- The tech stack should match your team’s capacity and long-term goals.
- Build only where it gives you a competitive edge; buy or partner for everything else.
- The right partner, like DEVtrust, helps you move faster with less risk and better outcomes.
What You Must Understand Before Building AI
Most AI projects fail because teams proceed directly to development without an adequate understanding of what AI is and isn’t. If you’re leading AI efforts internally, success starts with clarifying what you’re trying to build, why you’re building it, and what constraints shape your architecture.
AI is not a single tool or platform. It’s a system that learns patterns from historical data to make predictions or automate decisions. What you need to build is narrow AI, a model tailored to a well-defined task like identifying high-risk leads, predicting churn, or recommending products.
Before choosing any algorithm, first ask if the problem requires AI or if a more straightforward, faster solution already exists. A good candidate problem is repetitive, data-rich, and time-consuming for humans to do manually. Tasks like fraud detection, quality control, or ticket routing often meet that bar.
You also need clarity on how precise your AI needs to be. Some use cases can tolerate occasional misses; others can’t. That distinction should guide your architectural choices from the start.
Finally, assess your internal readiness. Do you have access to enough labeled, reliable data? Can your infrastructure support high-throughput data processing and model inference? Does your team have machine learning expertise, or will you need external help?
Once you’re clear on what AI should solve and how it fits into your stack, it’s essential to understand how AI development differs from traditional programming. That distinction helps set the right expectations before you move into the building. Let’s break that down next.
How AI Development Differs from Traditional Programming
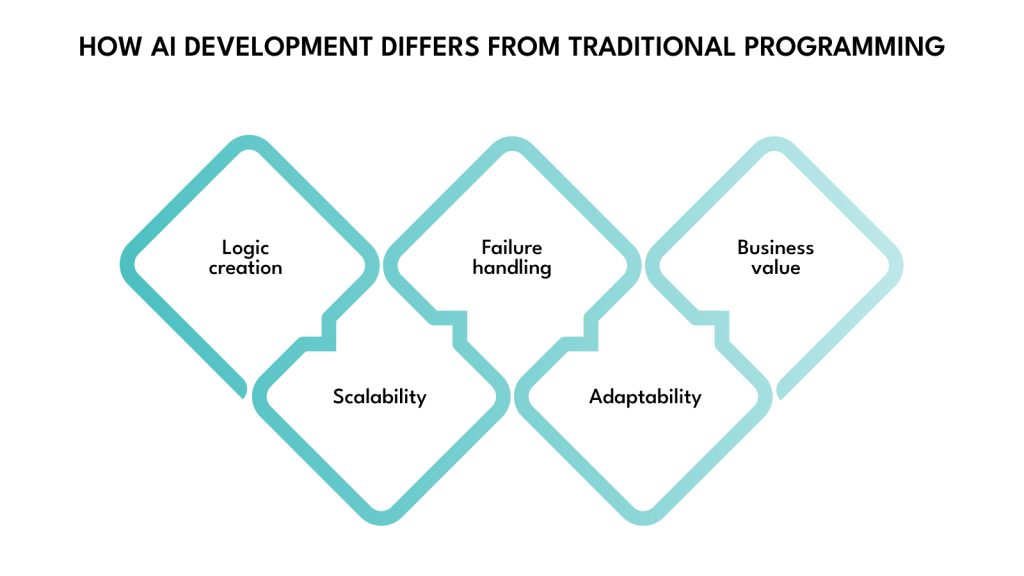
AI systems don’t follow traditional logic-based programming. Instead of explicitly coding rules, you train models on data to learn behavior. This fundamental difference shapes how teams build, test, and deploy AI.
In a traditional system, developers write step-by-step instructions to define how the program behaves. It works when logic is predictable and rule-based. However, the moment you’re dealing with ambiguity, patterns, or scale, such as detecting fraud, forecasting demand, or prioritizing support tickets, this approach starts to break down.
AI shifts the focus from manual rule creation to pattern learning. Instead of coding instructions for every situation, you train a model on real data and let it learn how to respond.
Here’s how the two approaches differ and why AI often wins in modern business environments:
- Logic creation: Traditional programming depends on the developer knowing every rule. AI systems infer those rules by learning from historical outcomes, making them faster to adapt to complex or noisy environments.
- Scalability: Rule-based systems become more complicated to manage as conditions grow. AI models, once trained, can scale effortlessly, even improving over time with retraining and feedback loops.
- Failure handling: Bugs in traditional code are binary; you either fix the logic or not. In AI, failure modes are continuous and trackable through confidence scores, model drift indicators, and probabilistic behavior, offering more control at scale.
- Adaptability: Every behavior change requires a code rewrite in traditional systems. AI systems evolve by updating training data, making them more resilient to market shifts, customer behavior changes, or business pivots.
- Business value: Traditional automation improves efficiency in known processes. AI opens new revenue and product opportunities by solving problems that were too expensive or time-consuming to automate before.
That doesn’t mean AI is always the right answer, but when the problem involves variability, volume, or predictive complexity, traditional programming can’t compete. AI brings a level of speed, flexibility, and intelligence that static systems simply can’t match.
Now that the differences are apparent, let’s go into the actual development process, which involves building AI that works in real business environments, from defining the problem to production deployment.
How to Make Your AI System: Complete Step-by-Step Process
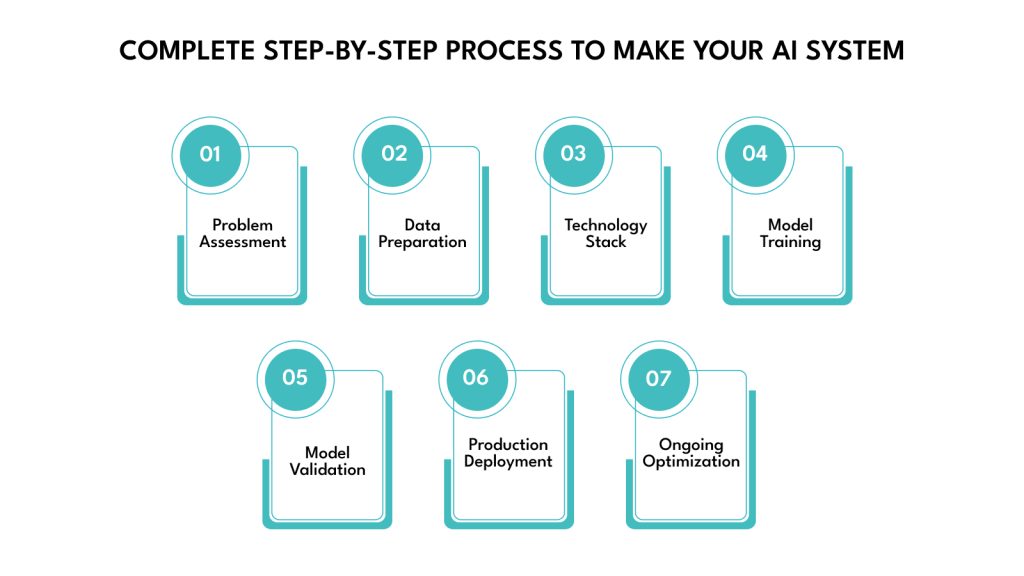
This seven-step process takes you from business problem to production deployment. Each step builds on the previous one, creating a systematic approach that minimizes risk and maximizes your chances of success.
Step 1: Define Your Problem and Assess Feasibility
Before choosing tools or writing any code, clarify what you want AI to solve. Too many teams start with a model in mind instead of a well-defined problem. This leads to vague objectives, misaligned outcomes, and wasted resources.
Start with a single, clear business problem rooted in operations, decision-making, or inefficiencies. Focus on issues where AI can create direct value, automate repetitive work, classify incoming inputs, forecast outcomes, or ranking options based on likelihood or priority.
Ask these questions to shape the problem:
- What internal process or decision consistently consumes time or lacks accuracy?
- What data do we already collect around this process?
- What would a better outcome look like—and how would we know it’s working?
- Do we need real-time predictions, or is batch processing sufficient?
- Does solving this with AI offer a meaningful advantage over rules or manual logic?
Once the problem is defined, assess feasibility on three fronts:
1. Business Value: Estimate how solving this problem affects core metrics, revenue, efficiency, cost, or customer experience. If the impact is minimal or hard to measure, AI might not be worth the investment here.
2. Data Availability: Check if you have enough structured, relevant, and accessible data to train a model. Missing or biased data makes even the most promising use case risky.
3. Technical Fit: Determine if AI is the right approach or if traditional automation, simple heuristics, or basic analytics could deliver faster results with less overhead.
This step builds the foundation for everything that follows. If the problem is unclear or if AI is not the right solution, no model will fix that later.
Step 2: Collect and Prepare Your Data
Data quality is critical since your model is only as good as the data behind it; inaccurate or biased data leads to unreliable predictions and poor business outcomes. Before model selection, you need to build a reliable, representative dataset.
That starts with knowing what data you already have and where the gaps are.
1. Audit What You Have
Start with a detailed review of every internal data source that touches your problem area. Pull from databases, product logs, CRM systems, spreadsheets, or APIs. For each source, document:
- What fields are available, and how frequently are they updated
- How much historical data do you have
- Where the gaps, inconsistencies, or duplications exist
- Who owns the data, and what access controls apply
If your current system does not log the information needed, this is the time to update logging mechanisms, not later.
2. Fill the Gaps With External or Proxy Data
For early-stage AI efforts, internal data is often incomplete. Depending on your use case, you can enrich your dataset with third-party sources, public datasets, scraped content, industry benchmarks, or data from partners.
Look for coverage diversity: seasonality, edge cases, platform variants, or different user types. The model must learn from real-world variety, not idealized samples.
3. Prepare and Preprocess Thoughtfully
Data preparation is not a cleanup task; it’s a technical step with business implications. You’ll need to:
- Handle missing values with consistent strategies (imputation, discards, flags)
- Normalize or encode variables so that models can work with them
- Align time zones, IDs, and formats across systems
- Consolidate redundant or overlapping sources
Use tools like Pandas, NumPy, or dbt to streamline these tasks. But don’t rush. Teams often underestimate this phase; it usually takes more time than model development.
4. Design for Ongoing Quality, Not One-Time Cleanup
Set up automated checks to catch anomalies in data pipelines: sudden spikes, nulls, formatting errors, or schema changes. Build validation logic into your ingestion scripts. Alert when thresholds are breached. This reduces future model drift and unexpected failures.
5. Split the Dataset for Training, Validation, and Testing
Once your dataset is cleaned and structured, divide it into training, validation, and testing sets. This helps the model learn, fine-tune, and prove itself on unseen data. Follow practical standards like Google’s dataset splitting guide, which recommends reserving around 15% of your data for validation and testing.
Make sure your splits reflect real-world usage, and not just random cuts, so your model can generalize accurately. Avoid data leakage, ensure these sets don’t overlap, and respect time-based splits if the task is predictive.
Step 3: Choose Your Technology Stack
The next step is selecting the right technology, one that fits your use case, team capability, and future support plans. These choices shape not just development speed but also how scalable, maintainable, and resilient the system becomes.
Programming Language
Python remains the default choice for AI projects. Its ecosystem is mature, reliable, and optimized for every phase of development, from preprocessing to deployment. Libraries like scikit-learn, TensorFlow, and PyTorch are Python-native, with wide adoption and community support.
Use it unless technical constraints demand otherwise, like an existing enterprise Java stack or legacy infrastructure that limits flexibility. In such cases, plan how ML code will integrate cleanly without excessive workarounds.
Frameworks
AI frameworks are the core tools that define how models are structured, trained, and moved into production. They shape everything from iteration speed to deployment reliability.
Use PyTorch when rapid experimentation and flexibility are critical. It’s easier to debug and ideal for early-stage prototyping or research-driven projects.
Use TensorFlow when production-readiness and scalability are priorities. It integrates with TensorFlow Serving and supports model versioning and lifecycle management.
Cloud Infrastructure
Major cloud providers offer powerful AI tooling, but misaligned choices can drive up cost and complexity fast.
- AWS gives deeper control, ideal if your systems already run on it—but expect more hands-on configuration.
- Google Cloud offers an ML-focused stack with tools like Vertex AI and BigQuery ML that speed up early adoption.
- Azure integrates well within Microsoft-heavy environments and supports AI pipelines with tools like Azure ML and Power BI.
Separate your environments clearly:
- One for experimentation, where flexibility and debugging matter.
- Another for production, with monitoring, security, and resource scaling in place from day one.
Development Environment and Collaboration
Early exploration benefits from notebooks like Jupyter or Colab, especially for smaller datasets or model testing. As the project matures, transition to structured development using VS Code, Docker, and Git.
Establishing shared coding standards, proper version control, and reproducible environments reduces friction during model handoff, review, and deployment. This is where most AI initiatives face scale-related delays; structure avoids them.
Step 4: Design and Train Your Model
Create the algorithmic framework that will solve your specific problem.
- Choose the right algorithm – Match your problem type to the appropriate algorithms. Use regression models for prediction problems like sales forecasting. Classification algorithms like logistic regression work for spam detection or customer segmentation. Recommendation problems need collaborative filtering or content-based approaches.
- Start simple, then iterate – Begin with basic models before trying complex approaches. Linear regression, logistic regression, and decision trees often provide good baselines. Complex models like neural networks require more data and expertise but may not perform better for your specific problem.
- Train your model – Load training data into your development environment, configure hyperparameters like learning rate and training iterations, and then run the training process while monitoring progress. Use cross-validation to ensure your model generalizes well to new data.
- Evaluate performance metrics – Measure accuracy (percentage of correct predictions), precision (how many positive predictions are correct), and recall (how many actual positive cases you identify). For regression problems, track metrics like mean absolute error and root mean square error.
- Iterate and improve – If performance doesn’t meet targets, try adding more training data, engineering new features from existing data, adjusting model parameters, or experimenting with different algorithms. This iterative process continues until you achieve acceptable performance.
Step 5: Test and Validate Your Model
Rigorous testing prevents costly failures when your model encounters real-world conditions.
- Test on unseen data – Use your reserved test dataset to measure final performance. This provides an honest assessment of how your model will perform in production, free from training bias.
- Validate against edge cases – Test your model with unusual inputs like missing data, extreme values, or data patterns it hasn’t seen before. Document how your model handles these scenarios and implement appropriate safeguards.
- Conduct error analysis – Examine incorrect predictions to identify patterns. Are certain customer segments consistently misclassified? Do errors cluster around specific data ranges? This analysis guides targeted improvements.
- Validate business impact – Run your model on historical data with known outcomes. Calculate the exact money, time, or effort your model would have saved. This quantifies value and builds stakeholder confidence.
- Test system integration – Verify your model works with the existing infrastructure. Test data flow from source systems, confirm predictions are stored correctly, and validate that results display properly in user interfaces.
Step 6: Deploy to Production
Now, it’s time to transform your validated model into a live system that delivers business value.
- Build production API – Create a web service that accepts input data and returns predictions. Implement authentication to control access, rate limiting to prevent system overload, and comprehensive error handling for invalid inputs or system failures.
- Deploy to infrastructure – Move your model to production using cloud services like AWS Lambda, Google Cloud Functions, or containerized deployments with Docker. Configure storage for predictions and performance data. Set up load balancing and auto-scaling to handle varying demand.
- Integrate with applications – Connect your AI model to systems that need predictions. Modify application code to call your AI API, update user interfaces to display results, and configure automated workflows that act on predictions.
- Implement monitoring – Set up comprehensive tracking for model performance and system health. Monitor accuracy trends, response times, error rates, and usage patterns. Configure alerts for performance degradation or system failures.
- Create rollback procedures – Develop plans for quickly reverting to previous model versions if problems occur. Test these procedures before you need them to ensure rapid recovery from issues.
Step 7: Monitor and Continuously Improve
It’s always recommended to monitor your AI system after deployment, as performance degrades without warning if data patterns shift or models go stale. You can follow the pattern below to monitor and continuously improve:
- Observe model performance – Track key metrics weekly, including accuracy trends, data drift, and business impact. Set up automated alerts when performance falls below acceptable thresholds. Monitor for changes in input data patterns that might affect model accuracy.
- Collect feedback data – Gather information about model performance from users and business outcomes. Track what actually happens after predictions are made. Use this feedback to identify areas for improvement and validate model effectiveness.
- Retrain regularly – Update your model with new data to maintain accuracy as conditions change. Schedule monthly retraining using the latest data, automate the retraining process to reduce manual effort, and test new model versions before replacing production models.
- Optimize for scale – Improve system performance by reducing model size without losing accuracy, implementing caching for frequently requested predictions, and adjusting computing resources based on usage patterns. Profile resource usage to identify bottlenecks and optimize accordingly.
- Growth plan – Prepare for increased usage by testing system capacity, estimating future resource needs, and considering deployment strategies like edge computing for latency-sensitive applications. Build modular architectures that support the independent scaling of different components.
Programming Languages Commonly Used in AI Development
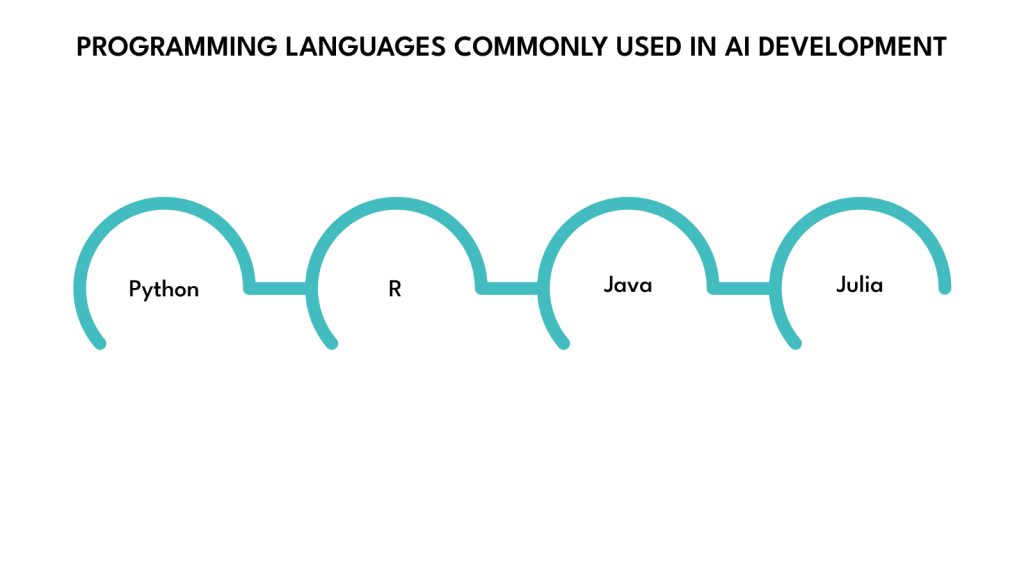
Choosing the correct programming language is a crucial yet early step in building AI systems. While tools and frameworks matter, the language you build in affects everything from development speed to integration complexity and team scalability.
Python is the most widely used option, but it’s not the only one. Depending on your project goals, infrastructure, and team expertise, other languages can play a critical role. Below are four languages often used in AI projects, along with practical guidance on when to use each.
Python
Python is the most popular language in AI for a reason. It has a mature ecosystem, readable syntax, and deep integration with the libraries and frameworks that drive machine learning today. From data handling (Pandas, NumPy) to model development (TensorFlow, PyTorch) to deployment (FastAPI, Flask), Python supports the whole AI workflow.
Its large community ensures long-term support, frequent updates, and access to reusable components. Python also integrates well with Jupyter notebooks, making it ideal for experimentation, quick prototyping, and collaborative research.
- When to use it: You can use Python for most AI projects, especially if you’re working with standard ML frameworks or looking to scale quickly with an existing talent pool.
R
R was initially built for statistical computing and data visualization. While not as versatile as Python, it’s still used by data scientists and academic teams who prioritize statistical rigor and exploratory analysis. R offers robust packages like caret and randomForest for model building, though it’s less suited to deep learning or production deployment.
R has powerful visualization capabilities and supports advanced statistical models out of the box, but its ecosystem is not optimized for scaling or deployment across modern infrastructure.
- When to use it: Use R when your AI efforts are research-heavy, focused on data analysis or reporting, and not intended for production environments.
Java
Java is not the first language most people associate with AI, but it plays a significant role, especially in enterprises with established Java ecosystems. Java offers strong performance, easy multithreading, and wide use in large-scale systems.
Frameworks like Deeplearning4j and Weka provide machine learning support, and their stability makes them a safe choice for integrating AI into backend systems, APIs, or enterprise platforms. However, Java’s verbosity can slow early-stage experimentation compared to Python.
- When to use it: Use Java when your infrastructure is already Java-based or when your AI models need to integrate tightly into legacy enterprise systems.
Julia
Julia is a newer language designed for high-performance numerical computing. It combines the speed of C with the readability of Python, which makes it well-suited for computationally intensive tasks like large-scale simulations, mathematical modeling, or high-dimensional data processing.
Although Julia’s AI ecosystem is growing, it’s still relatively small compared to Python. Libraries like Flux and MLJ are promising, but adoption is limited outside of academia and advanced research.
- When to use it: When performance is critical, and you’re working in a domain where numerical precision and speed are more critical than ecosystem maturity.
Build vs Buy vs Partner: Making the Right Choice
Creating your own AI setup can offer control and customization, but it’s not always the smartest use of time or resources. Before committing, assess if building from scratch supports your business goals and delivery timelines. This decision shapes how fast you move, what control you retain, and how much technical debt you take on. It is one of the most important calls you’ll make.
Think of this as a bonus checkpoint. If you’ve followed the earlier steps, you’re ready to build, but now’s the time to ask if you should.
When Building is the Right Call
Build AI in-house when you have:
- Proprietary data that no vendor has access to
- Very specific use cases that off-the-shelf tools cannot support
- Strict integration needs with your existing systems
- Long-term technical capacity to maintain and evolve models
For example, if you’re working with sensitive medical records or need AI to fit deeply into your custom logistics stack, commercial APIs may not give you the control or accuracy you need.
But remember, building comes with responsibility. You own everything: performance, reliability, and compliance. The engineering effort is just the beginning; ongoing model updates, infrastructure costs, and cross-functional coordination continue long after launch.
When Buying Off-the-Shelf Makes More Sense
If your use case is well-defined and non-differentiating, like document classification, object detection, or simple customer support automation, buying a prebuilt solution is faster and more cost-efficient.
Commercial APIs from OpenAI, Google Cloud, AWS, and Azure cover most standard needs. These tools give you scale and reliability out of the box, with less overhead.
Still, you need to evaluate:
- Accuracy in your domain: Does the model handle your terminology or edge cases?
- Integration effort: How easily does it connect to your data and systems?
- Control over inputs and outputs: Are there transparency or explainability limits?
- Vendor lock-in risks: What happens if pricing changes or features are deprecated?
Buying works best when speed is a priority and customization isn’t mission-critical.
When Partnering Brings the Best Balance
For many teams, partnering with DEVtrust is the most efficient way to build real AI products without slowing down or hiring an entire ML team from scratch. We work closely with product leaders, CTOs, and founders to turn high-stakes AI ideas into working systems that scale.
Partnering makes sense when:
- You don’t have in-house AI talent but need tailored solutions
- You’re aiming to move fast without locking yourself into rigid systems
- You’re exploring new use cases and want technical clarity before scaling
Look for partners who’ve solved similar problems in your industry. Choose a company like DEVtrust, with hands-on experience across finance, healthcare, and logistics that helps you move with clarity and reduce build-to-risk from day one.
If you’re still unsure between building, buying, or partnering, book a quick call to get a second opinion on what works best for you.
Maintaining AI Systems After Deployment
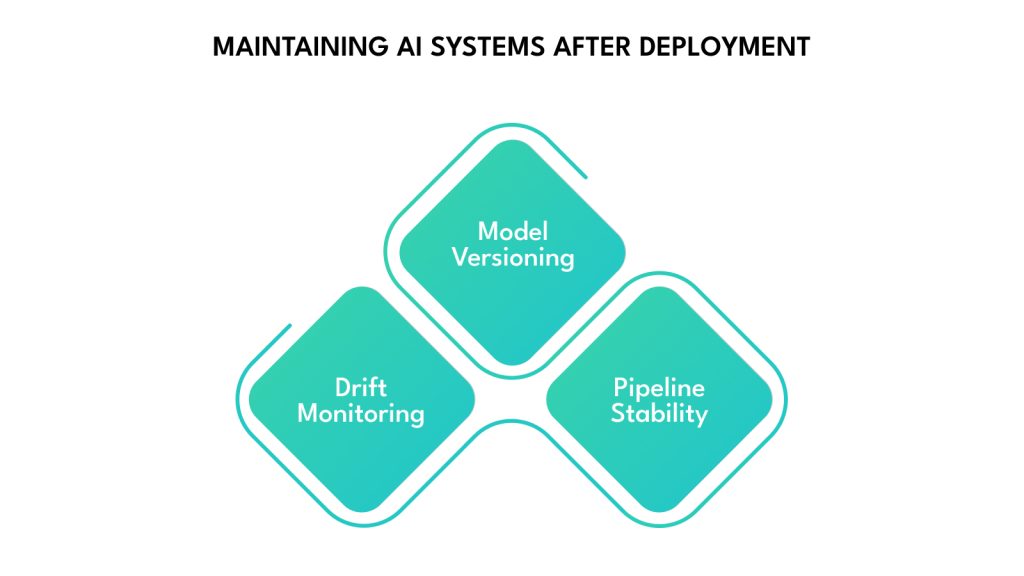
Even a well-trained AI model will decline in performance over time if it is not adequately managed. Data patterns shift, business needs evolve, and technical environments change, making it essential to treat AI systems as living components, not one-time builds.
A production AI system requires three layers of continuous maintenance:
1. Performance Monitoring and Data Drift Detection
Models perform well initially because they’re trained on known, structured patterns. However, once deployed, real-world data often shifts, sometimes gradually and sometimes suddenly. This is known as data drift. Without early detection, AI output becomes less reliable, which erodes user trust and negatively impacts business.
Set up automated monitoring that tracks key indicators, such as prediction confidence, input distributions, and output consistency. Utilize statistical techniques or drift detection libraries (e.g., EvidentlyAI, Alibi) to notify your team when inputs cease to match the training conditions.
2. Retraining and Model Versioning
Retraining cycles should be part of your AI lifecycle planning, not a reactive task. New data needs to be collected, labeled, and incorporated into updated versions of your model regularly. How often you retrain depends on usage volume and data volatility, but most systems benefit from monthly or quarterly refreshes.
Versioning matters just as much. Track changes between models—code, data, and performance metrics—so you can compare effectiveness and rollback when needed. Tools like MLflow, DVC, or Vertex AI Pipelines help automate this process.
3. System Maintenance and Pipeline Stability
Behind every AI system is a set of pipelines—data ingestion, preprocessing, model inference, and output delivery. These pipelines can break silently if API contracts change, data sources are deprecated, or upstream transformations shift.
Invest in unit tests for data schema validation, API integrity checks, and output consistency monitoring. Maintain logs and alerts that extend beyond system health and accurately reflect business operations. A reliable AI system stays aligned with the business problem it was built to solve.
Strong systems and routines are helpful, but most AI projects still encounter friction during execution, data limitations, integration issues, and misaligned teams are common and need to be addressed early.
Common Challenges and How to Overcome Them
Even with the right process, developing AI systems is rarely straightforward. Most projects hit the same set of hurdles: quality issues, technical bottlenecks, and organizational blockers. These come up when teams move fast without fully scoping the technical and organizational effort.
Here’s how to spot and fix the most common problems before they slow you down.
1. Data and Model Challenges
Problem: Poor data leads to poor models. Incomplete, biased, or overly narrow datasets limit your model’s ability to perform in production.
What to do:
- Run structured data audits before training. Check for missing values, mislabeled classes, and sampling bias across key user segments.
- Use synthetic data to augment edge cases or rare conditions if real-world examples are limited.
- Diversify your training sets with data from different periods, user types, and operational conditions to improve generalization.
Problem: Your model performs well in testing but fails when deployed.
What to do:
- Validate on production-like data, not just clean test sets.
- Deploy incrementally and monitor behavior in live environments with real users.
- Track failure patterns early on to adjust your inputs or architecture before scaling.
Problem: Model performance degrades over time as user behavior or external conditions change.
What to do:
- Set up performance monitoring and data drift detection from day one.
- Automate retraining cycles based on new labeled data.
- Create alerts that flag changes in prediction quality or input patterns.
2. Technical and Infrastructure Challenges
Problem: Infrastructure costs spiral beyond initial estimates, especially during training or scaling.
What to do:
- Design leaner models that use fewer compute resources during inference.
- Use cloud credits wisely by benchmarking before committing to large clusters.
- Continuously optimize serving architecture, from batching strategies to memory handling.
Problem: Latency issues in real-time applications degrade user experience.
What to do:
- Profile your system to find the true bottlenecks (model size, network, data loading).
- Use edge deployment for low-latency use cases or precompute predictions when real-time isn’t mandatory.
- Cache outputs for repeated inputs when relevant.
Problem: Integrating AI into legacy systems takes more time than expected.
What to do:
- Define clear API contracts and data schemas early on.
- Decouple components so AI pipelines can evolve independently from legacy systems.
- Test integrations in staging environments that mirror production closely.
3. Organizational and Process Challenges
Problem: Your team lacks the AI-specific skills required for production-grade development.
What to do:
- Upskill with targeted training for key team members, not general-purpose AI courses.
- Partner with technical consultants who specialize in AI systems.
- Take initial phases as learning sprints where internal teams shadow external experts.
Problem: Unrealistic deadlines lead to shortcuts that hurt long-term reliability.
What to do:
- Set expectations early, especially with leadership, on the experimentation and validation AI requires.
- Plan buffer time into every stage, from data prep to deployment.
- Use agile but technically grounded roadmaps with measurable checkpoints.
Problem: Coordination between data scientists, engineers, and business teams breaks down.
What to do:
- Align on success metrics that all teams care about.
- Set shared documentation standards across roles.
- Run weekly alignment meetings between product, ML, and ops to catch miscommunication early.
Future-Proofing Your AI Investment
Building AI systems that remain valuable over time requires careful architectural decisions and strategic planning. Technology evolves rapidly, but good design principles and business alignment create lasting value.
Building for Long-term Success
Design modular architectures to allow easy updates. This means components can be reused or replaced independently. Separate key functions like data processing, model inference, and business logic into different services to simplify maintenance. This approach simplifies updates and reduces technical debt.
Implement continuous learning and adaptation capabilities. Static models degrade over time as conditions change. Implement automated feedback loops that collect performance metrics and trigger retraining workflows to adapt your AI models as data and conditions evolve.
Plan vendor relationship management and exit strategies. Avoid excessive dependence on specific AI services or platforms. Maintain flexibility to switch providers or bring capabilities in-house.
Invest in team capabilities and knowledge retention. AI expertise provides sustainable competitive advantages. Build internal capabilities while leveraging external resources strategically.
Conclusion
Building AI from scratch requires significant technical expertise, substantial resources, and careful planning. Most organizations benefit from hybrid approaches that combine commercial services with selective custom development.
Success in AI depends on clear business objectives, realistic resource planning, proper technical execution, and choosing the right approach between building, buying, or partnering.
Start with a clear problem definition and success criteria. Evaluate commercial solutions thoroughly before committing to custom development. Build internal capabilities gradually while delivering incremental value.
Focus on solving specific business problems with measurable outcomes. Invest in data quality, team capabilities, and proper infrastructure. Plan for long-term success rather than quick wins.
DEVtrust helps tech teams build AI that’s grounded in real business needs. From early scoping to production deployment, we bring the technical clarity and execution support that complex projects require.
Book a quick call, and we’ll help you pressure-test your approach before you commit.
How to Make Your AI from Scratch: Complete Guide
Create your AI from scratch with our guide. Learn essential prerequisites, data management, model building, and deployment. Start building now!
Contact Us

