
Businesses are moving past rule-based systems as users expect applications that interpret information, adapt in real time, and reduce manual effort. With the global AI market expected to reach USD 684.6 billion by 2032, the shift toward machine learning app development has become a practical requirement rather than a technical experiment.
Teams across finance, healthcare, logistics, and education now rely on machine learning app development to automate tasks such as document extraction, fraud detection, and forecast modeling. These capabilities give apps the ability to handle complex patterns without relying on hard-coded logic.
This blog outlines the core elements of ML-powered apps, the types of models used, the tech stack behind them, and how DEVtrust helps teams bring ML features into production with clarity and predictable delivery.
Key Takeaways
- Machine learning app development strengthens critical workflows by handling tasks that rule-based logic cannot, such as risk scoring, document parsing, and route forecasting.
- Strong machine learning app development performance depends on the supporting architecture, including data pipelines, inference layers, drift monitoring, and controlled model updates.
- Different ML categories, supervised, unsupervised, deep learning, reinforcement, and hybrid models, serve distinct use cases across finance, healthcare, logistics, and education.
- Choosing the right tech stack affects latency, security, and deployment speed across on-device inference, backend serving, and mobile environments.
- DEVtrust helps teams move ML features from concept to production through structured delivery, skilled engineering, and a lifecycle approach to model training, testing, monitoring, and updates.
What Defines a Machine Learning App?
A machine learning app uses trained models to make predictions or decisions that fixed rules cannot manage. The app collects inputs such as transactions, location data, images, or text, sends them to a model, and adjusts its behavior based on the output.
The model can run in two places. Mobile-focused products often use on-device formats such as TensorFlow Lite or Core ML to keep inference fast and reduce reliance on network calls. Apps that require heavier computation, such as fraud scoring or document extraction, route data to a backend service running a containerized model with GPU support.
Real examples include:
- A FinTech app assigns a transaction risk score before approval
- A logistics tool predicting arrival delays using GPS patterns
- A healthcare workflow extracting PHI from lab reports with OCR and NLP
- An EdTech platform adjusting lesson difficulty based on student performance data
A true ML-driven app depends on more than a trained model. It requires clean data pipelines, monitored inference endpoints, drift alerts, and controlled model updates. Without these components, prediction quality drops quickly in fast-changing fields like finance or healthcare.
In practical terms, a machine learning app follows a continuous loop: data in, model inference, action taken, monitored performance, and periodic model updates. When this loop influences core product behavior, the app qualifies as ML-powered.
As soon as the core structure of an ML-powered app becomes evident, it becomes easier to see where these capabilities create measurable value inside real products.
Strategic Reasons to Build with Machine Learning
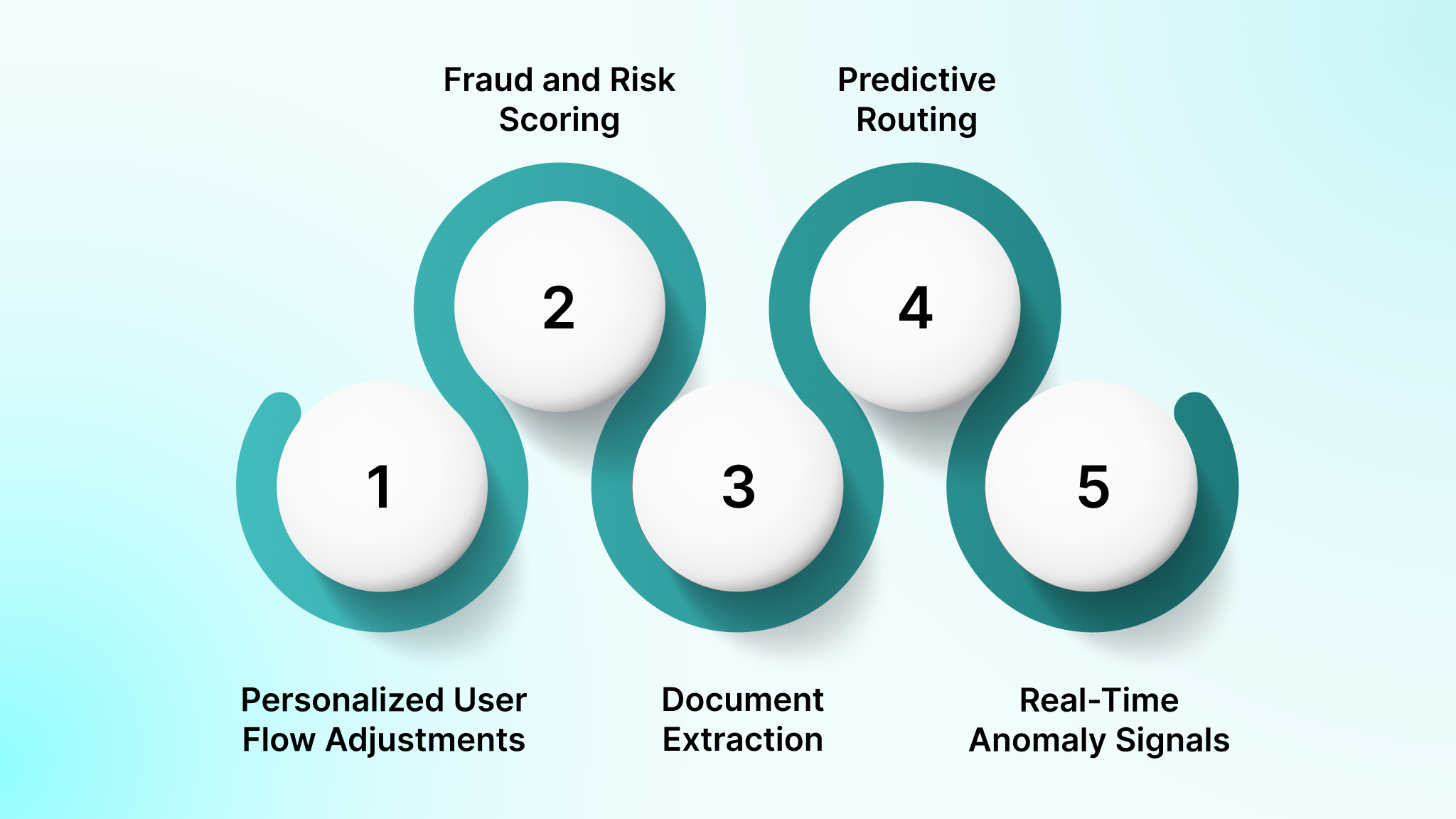
Machine learning adds value when an app must analyze patterns, interpret unstructured data, or make real-time decisions that fixed logic cannot support. It strengthens both user experience and backend workflows by replacing manual steps with reliable, data-driven outputs.
- Personalized User Flow Adjustments: ML models modify content, recommendations, or difficulty levels based on user behavior signals such as session depth, input accuracy, or navigation paths.
- Fraud and Risk Scoring at Transaction Time: Classification models evaluate location, device data, transaction history, and velocity patterns to identify suspicious behavior before approvals.
- Document Extraction for High-Volume Workflows: OCR and NLP pipelines convert invoices, ID documents, lab forms, or claim packages into structured fields that downstream systems can process automatically.
- Predictive Routing and Delay Detection: Models trained on GPS traces, traffic patterns, and historical service windows help logistics teams anticipate late arrivals and adjust dispatch plans.
- Real-Time Anomaly Signals for Stability: ML systems track usage anomalies, unusual API call sequences, or error clusters, giving engineering teams early warnings before performance issues escalate.
After mapping out the strategic value ML delivers, the focus turns to the specific categories of models that power those outcomes.
Types of Machine Learning Powered Applications

Machine learning applications fall into distinct groups based on how the model learns and the type of signal the app needs to generate. Each category supports a different engineering workflow, data structure, and deployment pattern, which directly shape how the app behaves in finance, healthcare, logistics, or education.
1. Supervised Learning Applications
Supervised learning is used when the app must map input data to a known output, such as classifying a document or predicting transaction risk. These models rely on labeled datasets and strict evaluation metrics.
Key Capabilities
- Transaction and Identity Scoring: Predicts fraud probability or customer verification confidence by analyzing device fingerprints, geo-velocity, historical transaction patterns, and authentication events.
- Structured Form Decisioning: Classifies onboarding packages, loan requests, or patient intake files using labeled examples tied to specific approval or triage workflows.
- Operational Forecast Outputs: Generates delivery ETA predictions, invoice payment likelihood, or claim approval timelines using historical process durations and exception patterns.
Example: A FinTech payout system assigns a transaction risk score before approval by analyzing prior behavior, device changes, and anomaly triggers.
2. Unsupervised Learning Applications
Unsupervised learning helps uncover structure inside raw datasets where labels do not exist. These models are valuable for segmentation, anomaly detection, and pattern grouping across high-volume systems.
Key Capabilities
- Usage Behavior Clustering: Groups customers based on journey paths, session heatmaps, and event frequencies to support targeted flows, adaptive UI layouts, or cohort-level experiments.
- Outlier Detection for System Stability: Monitors API latency distributions, packet loss bursts, irregular sensor readings, or unexpected transaction sequences to trigger engineering alerts.
- Inventory and Load Pattern Grouping: Identifies shipment classes, SKU velocity groups, or warehouse movement patterns that influence routing decisions and storage allocation.
Example: A warehouse platform groups SKUs by historical pick frequency to create optimized storage layouts that reduce travel time.
3. Deep Learning Applications
Deep learning models process unstructured inputs such as images, multi-page documents, recorded conversations, and free-form clinical notes. These apps require optimized inference pipelines and careful memory handling, especially on mobile.
Key Capabilities
- High-Fidelity Image Interpretation: Detects packaging damage, identifies product variants, analyzes dermatology images, or verifies document authenticity from camera captures.
- Multi-Layer Text Extraction: Converts scanned lab reports, discharge summaries, policy documents, or KYC packets into structured entities with token-level accuracy, ready for downstream validation.
- Audio and Speech Instruction Parsing: Transforms user voice commands or agent call recordings into intents and entities that feed into workflow engines or support automation scripts.
Example: A logistics pickup app detects damaged packages by analyzing driver-uploaded photos using a convolutional model.
4. Reinforcement Learning Applications
Reinforcement learning fits environments where the app must adjust its output continuously based on reward signals or feedback loops. These use cases evolve through repeated interaction rather than static training sets.
Key Capabilities
- Adaptive Lesson Path Control: Adjusts question pools, difficulty levels, and remediation prompts in EdTech apps using accuracy streaks, dropout points, and time-to-complete metrics.
- Load-Aware Resource Allocation: Reassigns drivers, batches orders, or adjusts storage zones using real-time capacity, historical congestion, and reward signals tied to on-time performance.
- Dynamic Offer and Pricing Logic: Updates fee structures, delivery slot pricing, or promotional windows based on acceptance rates, inventory constraints, and system load.
Example: An EdTech platform adjusts lesson difficulty dynamically by rewarding faster mastery and penalizing repeated errors.
5. Hybrid Machine Learning Applications
Hybrid ML pipelines combine two or more model types to handle workflows that include text, structured fields, images, and streaming data in a single process.
Key Capabilities
- Multi-Stage Document Intake Flows: Uses OCR for extraction, supervised classification for routing, and anomaly detection for fraud checks across insurance, healthcare, or compliance-heavy onboarding.
- End-to-End Commerce Intelligence: Merges ranking models, NLP-based search scoring, and clustering signals to optimize product discovery, replenishment suggestions, and user journey flow.
- Predictive Operations Dashboards: Combines forecasting models, deep-learning log parsers, and outlier detection to identify risks in financial systems, fleet operations, or multi-region backend deployments.
Example: A financial onboarding system validates IDs by extracting text via OCR, classifying document type, and running anomaly checks to flag potential tampering.
Each model category brings its own architectural demands, which directly shape the tech stack required to support it.
Strengthen your product through AI models built for accuracy, faster processing, and dependable performance. Connect with DEVtrust to access dedicated engineers and full-cycle ML delivery.
Selecting the Right Tech Stack for Machine Learning App Development
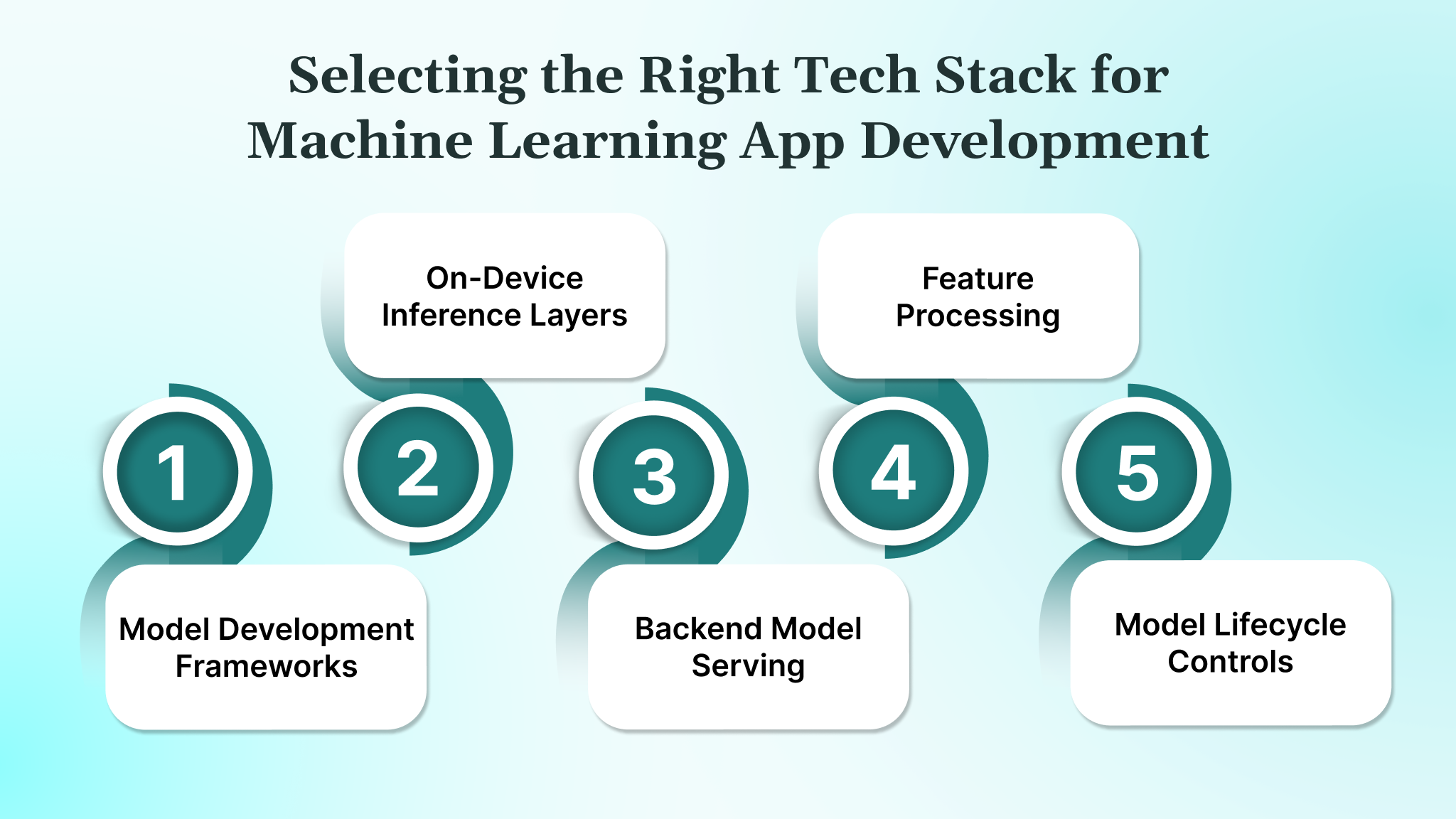
Choosing the tech stack for a machine learning application depends on where the model runs, how data flows through the system, and what constraints the app must meet for latency, security, and scalability. The stack shapes how quickly teams can train, deploy, and update models across mobile, web, or backend environments.
- Model Development Frameworks: Use established libraries such as PyTorch or TensorFlow to train models that handle structured data, multi-page PDF extraction, image inputs, or sequential behavior signals.
- On-Device Inference Layers: Adopt formats like TensorFlow Lite or Core ML when the app needs low-latency predictions on mobile, offline support, or privacy-focused workflows that keep data on the device.
- Backend Model Serving: Deploy containerized models behind REST or gRPC endpoints when handling heavier tasks such as fraud scoring, multi-step document processing, or high-volume transaction evaluation.
- Data Pipeline And Feature Processing: Build preprocessing flows using tools like Python-based ETL scripts or lightweight orchestration to clean, label, and transform data for supervised, unsupervised, or deep learning tasks.
- Monitoring And Model Lifecycle Controls: Track model accuracy, drift signals, and inference performance using logs, statistical checks, and controlled versioning to support regular updates without disrupting production flows.
The stack you choose also affects how quickly teams can execute, which raises an important question around internal capacity versus external support.
If you want a simpler way to compare mobile build approaches across platforms, start with this guide, Hybrid Mobile App Development: A Beginner’s Guide
Comparing In-House Teams with Outsourced Machine Learning App Development
Teams often debate whether to build ML-driven applications internally or partner with an external engineering group. The right choice depends on data maturity, required skill depth, delivery timelines, and the complexity of the ML workflows involved.
| Factor | In-House Development | Outsourcing To An External Team |
| Team Setup Speed | Slow, requires ML engineers, data specialists, backend developers, and QA hires. | Faster, external teams begin with established engineers and workflows already in place. |
| Skill Coverage | Limited to internal experience, which may not include OCR, NLP, forecasting, or anomaly detection. | Access to specialists across supervised, unsupervised, deep learning, and mobile inference workloads. |
| Infrastructure Readiness | Requires building ETL jobs, model serving layers, container setups, and monitoring from scratch. | External teams provide ready workflows for training, serving, testing, and controlled model updates. |
| Cost Structure | Higher due to salaries, onboarding, tooling, and infrastructure provisioning. | Predictable, scalable cost models aligned to scope, timeline, and required engineering depth. |
| Security And Data Handling | Internal teams must define access control, data isolation, and audit trails for sensitive workflows. | External partners follow structured development practices and documented data-handling rules suitable for regulated domains. |
| Delivery Predictability | Impacted by internal bandwidth and competing priorities across teams. | External teams operate on clear sprints, regular demos, and steady engineering velocity. |
Evaluating these approaches highlights how much execution quality depends on the partner driving the ML workflow.
How DEVtrust Delivers Reliable Machine Learning Applications
DEVtrust helps companies bring machine learning features into real products by combining strong engineering, clear communication, and a process that supports the full lifecycle of an ML system.
Whether you are adding OCR to an onboarding flow, building a behavior-based recommendation engine, or integrating conversational AI into a customer-facing product, DEVtrust stays involved from early requirements through deployment and ongoing updates.
- Full AI/ML Development Support: DEVtrust covers every stage of an ML initiative, including data preparation, model development, evaluation, integration, and deployment. Teams work across Python-based frameworks for model training, on-device formats for mobile inference, and backend systems that expose model predictions through secure API layers.
- Skilled Engineering Team: Engineers bring hands-on experience across supervised, unsupervised, and deep learning workloads. This includes OCR for document extraction, NLP for text interpretation, anomaly detection for backend stability, and classification models for risk or operational scoring. The team also manages the supporting components such as ETL flows, containerized model hosting, and monitoring.
- Dedicated ML Delivery Model: You get a consistent group of engineers and QA specialists who understand your domain, manage data nuances, and maintain the model lifecycle across training, testing, serving, and versioning. This consistency supports stable upgrades and reduces rework across releases.
- Smooth Collaboration With U.S. Product Teams: DEVtrust uses sprint-based delivery, shared documentation spaces, and overlapping working hours so product owners can review outputs, approve model updates, and refine acceptance criteria without delays. This is especially important for ML projects that require periodic evaluation or retraining.
- Quality, Testing, and Security Controls: The team follows secure coding practices, structured review cycles, and controlled test environments. ML outputs are validated for accuracy, drift, and edge-case behavior before integration. For conversational AI or chatbot work, DEVtrust uses proven platforms such as Dialogflow, IBM Watson Assistant, Microsoft Bot Framework, and Botpress to support intent recognition, entity handling, and workflow automation.
- Flexible and Scalable Delivery: You can start with a small ML-focused team for a single model or workflow, then expand into multi-model pipelines, analytics layers, or conversational interfaces as the product matures. DEVtrust supports ongoing maintenance, model retraining, and reporting so the system continues to improve after launch.
How DEVtrust Helped Credenza Build a Modern, Scalable Credential Platform
Credenza needed a secure, HIPAA-aligned platform for doctors to upload, manage, and share credentials, automate form filling, and handle high data volumes while guaranteeing accurate document extraction and MFA-based access.
- DEVtrust Solution: DEVtrust built a secure credential management system with MFA authentication, HIPAA-aligned encryption, AI-powered document extraction, and automated form population using OpenAI, plus a scalable Laravel and MySQL architecture with Twilio and Google Authenticator integrations.
- Result: Manual workload dropped by 45%, user satisfaction improved by 30%, credential verification delays fell by 25%, and the platform scaled to 1,000+ doctors within six months with strong performance and security ratings.
Conclusion
Machine learning app development helps teams move past static rules by integrating models that interpret data, score risks, extract information, and guide user flows. With clean data pipelines, monitored inference layers, and controlled model updates in place, ML features function as dependable parts of the product rather than experimental add-ons.
If you plan to introduce automation, document extraction, forecasting, or behavior modeling into your app, the right partner becomes crucial. The demands of machine learning app development extend beyond model training and require engineering patterns that protect accuracy, security, and long-term reliability.
DEVtrust supports these needs through structured delivery, deep experience across supervised and deep learning workloads, and steady communication with product teams. Whether you are building a new ML module or extending an existing product, our team helps you move from data preparation to production deployment with clarity and predictable output.
Ready to integrate ML into your roadmap? Connect with DEVtrust to bring your next ML-powered feature to production with confidence.

Frequestly Asked Questions
Related Articles
Mobile App Development
A Step-by-Step Framework for Business Mobile App Development
Mobile App Development
E-commerce Mobile App Development in 2026: Trends, Features, Cost, and ROI

Mobile App Development